
「ChatGPTのファインチューニングって何?」
「ChatGPTをファインチューニングする手順やメリットは?」
このように疑問を抱いている方もいるのではないでしょうか。
ChatGPTのファインチューニングを利用すると、業務の効率化が期待できます。
そこで本記事では、ChatGPTのファインチューニングの概要や手順を解説します。
最後に紹介するChatGPTをファインチューニングするメリットや注意点もぜひ参考にしてみてください。
ChatGPTのアカウント登録がまだの方は、以下の記事から登録方法を確認しましょう。

ChatGPTのファインチューニングとは
ファインチューニングとは、学習済みのChatGPTモデルに追加してオリジナルデータを学習させる技術のことです。
ChatGPTは2021年9月までのインターネット上にある大量のデータを事前学習しています。
2021年9月以降のデータはChatGPTにとって新たな情報となるため、新しいデータを含めた回答がほしい場合は、追加で学習させる必要があります。(2024年2月12日現在)
このように、事前学習しているChatGPTに、知識を追加で習得させることで新たなモデルを作り出せます。
ChatGPTでファインチューニングする手順
ChatGPTでファインチューニングする手順は、以下5STEPです。
参照:Open AI社公式Webサイト「Fine-tuning」
それぞれのSTEPを見ていきましょう。
STEP1:OpenAI APIキーを取得する
Open AI社のプラットフォームにアクセスしてください。
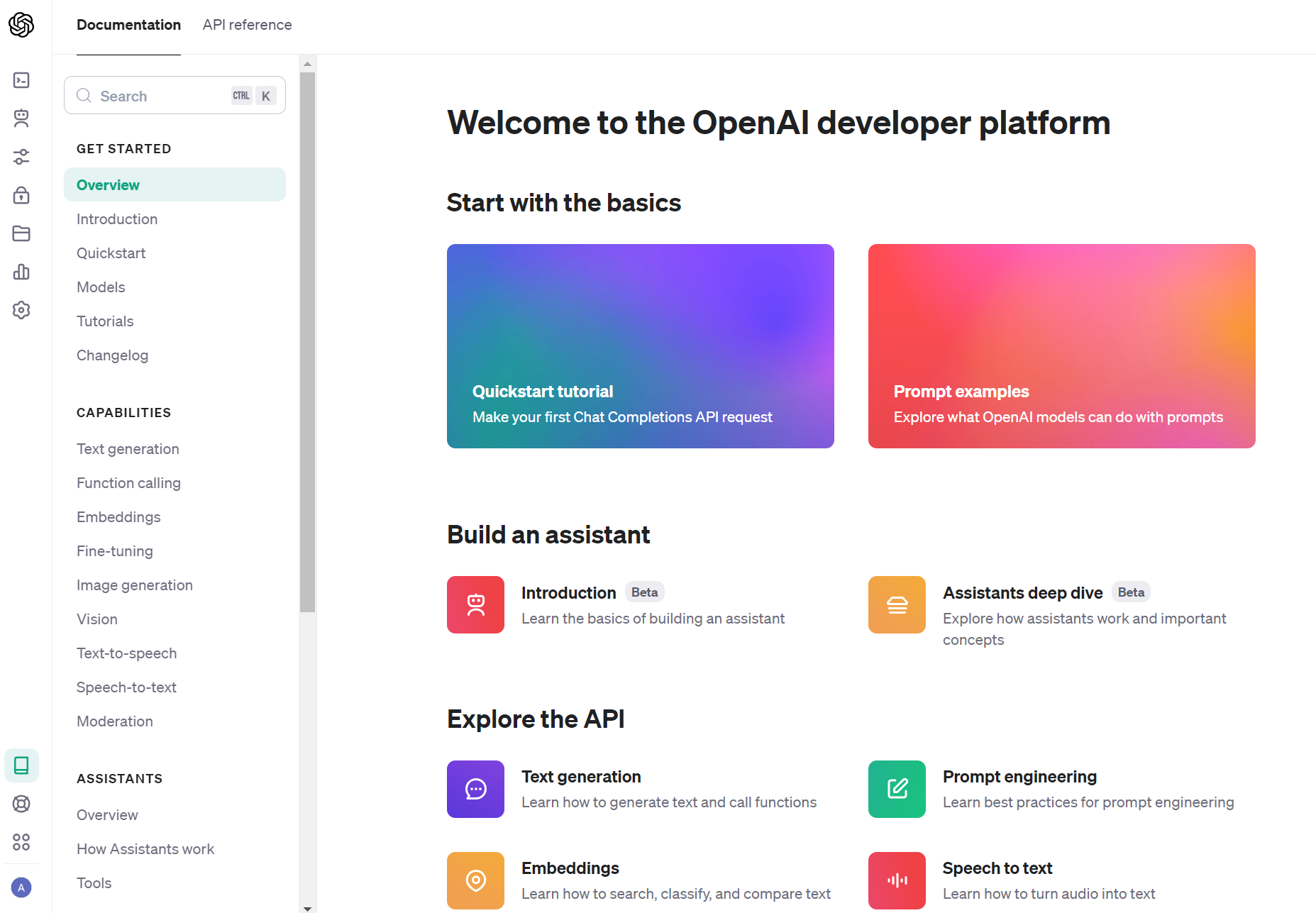
左上アイコンの上から4つ目の鍵アイコン「API keys」をクリックし、「+ Create new secret key」ボタンを押します。
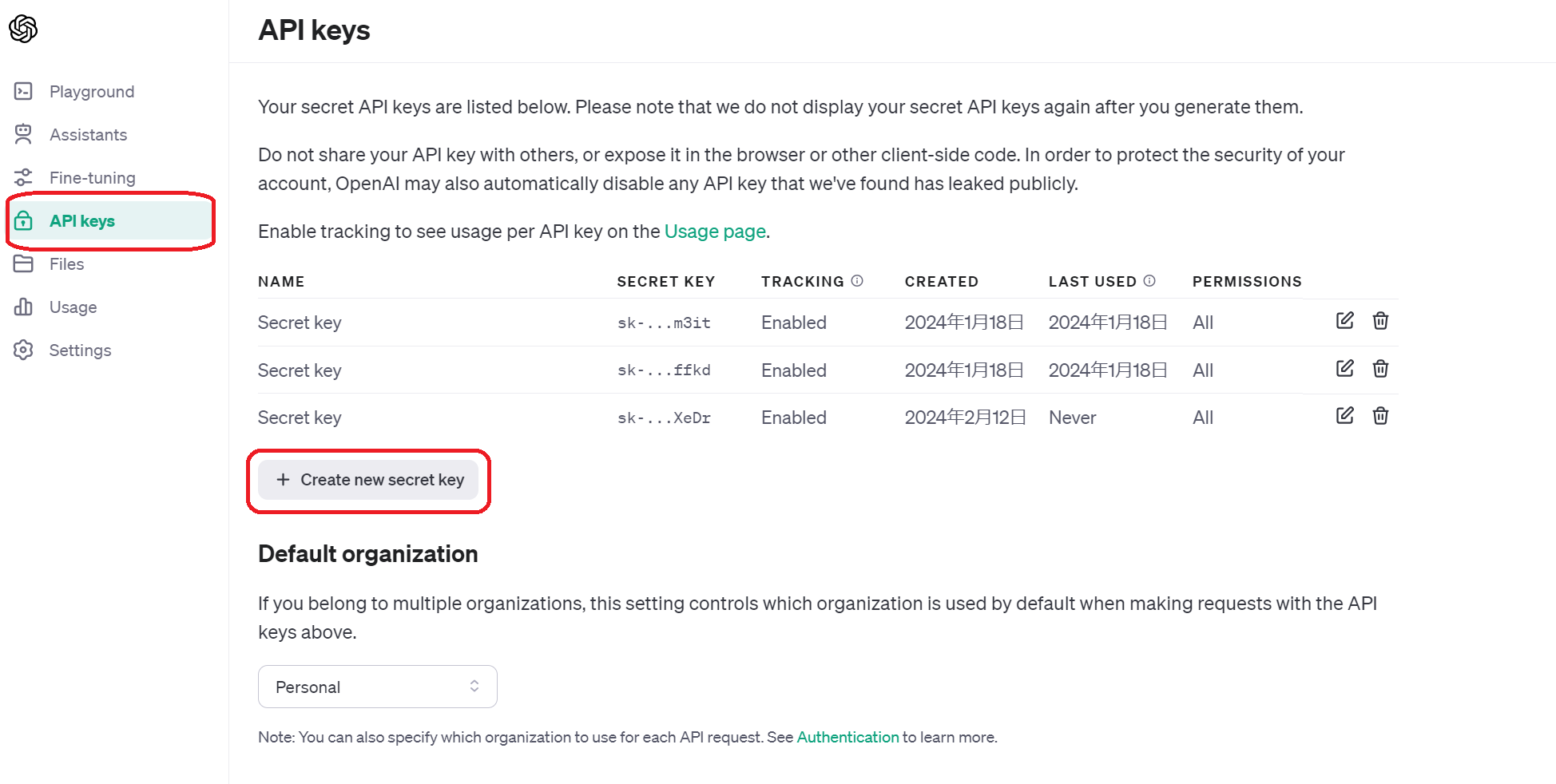
新しいAPIキーをコピーして入手してください。
STEP2:追加学習用のデータを準備する
ファインチューニングに使うデータは、質問と回答を組み合わせた「デモ会話」のセットを作成し、jsonlフォーマットで保存して準備してください。
ファインチューニングには、少なくとも 10個、通常であれば50~100個のトレーニングサンプルが必要とされています。
また、Open AI社のCookbookに載っているPythonコードから、トレーニングデータのフォーマットをチェックできます。ファインチューニング前に、エラーが表示されないか確認しておきましょう。
STEP3:追加学習用のデータをアップロードする
次に、ファイン作業環境を準備するために、PCのコマンド画面からPythonのOpenAIライブラリをインストールする必要があります。
PCの検索窓に「cmd」と検索し、コマンド画面を呼び出し、「!pip install openai」を入力します。
次の画面で、OpenAIのサイトでコピーしたAPI Keyをセットします。
import os
import getpass
os.environ[“OPENAI_API_KEY”] = getpass.getpass(“OpenAI API Key:”)
作成したファインチューニング用のデータセットを、以下のコードを使ってOpen AI社のサイトにアップロードしてください。
import json
import openai
# 学習用データのファイルパス
filepath = “(学習用データのファイルパスを入力する)”
# アップロード
train_file = openai.File.create(
file=open(filepath, “r”),
purpose=’fine-tune’
)
# 確認
print(train_file)
STEP4:モデルをファインチューニングする
アップロードされたデータをもとに、以下のコードを用いてモデルをファインチューニングします。
※今回の事例のモデルは「davinci」を使用しています。
# ファインチューニング実行
job_finetune = openai.FineTune.create(
training_file = train_file.id, model = ‘davinci’
)
このコードが実行されると、Open AI社のサイトでモデルがファインチューニングされます。
ただし、この時点ではファインチューニングの実行を待っている状態のため、すぐには実行されません。
また、以下のように、ファインチューニングの進捗状況を確認できます。
from datetime import datetime
# ファインチューニングのステイタス確認
finetune_data = job_finetune.list().data
print(finetune_data)
STEP5:ファインチューニングの結果を確認する
実行画面のStatusを確認してください。
「succeeded」は実行成功、「pending」は実行待ちの状態です。
全てのStatusが「succeeded」になれば、実行完了です。
以下のようなコードで質問をして、適切な回答が得られればファインチューニングは完了します。
希望の回答が得られない場合は、追加学習のデータから見直し、調整する必要があります。
# ファインチューニング後のモデルを指定
finetuned_model = ‘ファインチューニングのモデル名’
# プロンプトを定義
prompt = “〇〇とは何ですか?”
# 推論の実行
completion = openai.Completion.create(
model= finetuned_model, # 定義したモデルを指定
prompt = prompt, # プロンプトを指定
max_tokens = 1024, # 出力の最大文字数
n = 1, # 出力の数
stop = None, # 指定した単語が出現した場合に文章生成を停止
temperature = 0.5 # 出力の結果のランダム度合いを指定(0 – 2)
)
# 推論結果(completion)からテキストを取得
response = completion.choices[0][“text”]
print(response)
ChatGPTをファインチューニングするメリット
ChatGPTをファインチューニングするメリットは、以下3つです。
それぞれの内容をチェックしていきましょう。
ChatGPTをファインチューニングするメリット1:精度の高い回答が得られる
ファインチューニングによって、ChatGPTの学習モデルに追加学習させることで、特定のトピックに関して精度の高い回答が得られます。
追加で学習することで、通常のモデルよりも濃い情報を得られるため、さらにクオリティが高い結果を入手できるのがメリットです。
ChatGPTをファインチューニングするメリット2:長いテキストデータの学習ができる
ChatGPTは入力できるプロンプトの文字数に限りがあるため、長いテキストを入力しても内容を正しく読み取れません。
しかし、ファインチューニングを用いると長いテキストデータや多くの単語をトレーニングできます。
ChatGPTをファインチューニングするメリット3:回答出力までの時間を短縮できる
ファインチューニングを利用して回答を得ると、通常の対話よりもプロンプト入力から回答までの時間が短くなるため、業務をさらに効率化できます。
また、ファインチューニングを使ってChatGPTを学習させると、複雑で細かいプロンプトを入力する必要がなくなり、チューニングしたデータにより独自の回答を手に入れられます。
プロンプトが短くなるためChatGPTのトークン量も少なくなり、ファインチューニングの利用にかかるAPI使用料の節約が可能です。
Chatgptのファインチューニングに必要な料金
Chatgptのファインチューニングに必要な料金は、以下の4つの項目から判断されます。
また、それぞれのモデルの料金は以下のとおりです。(2024年2月12日現在)

ChatGPTモデルごとの最新料金プランを知りたい場合は、OpenAI公式サイトの価格ページからご確認ください。
ファインチューニングの料金の支払い方法
ファインチューニングの料金は、クレジットカードで支払えます。
支払い用のクレジットカードは、Billing画面の「Add payment details」から登録可能です。
Billing画面では、自分のアカウントのクレジット数をチェックできます。
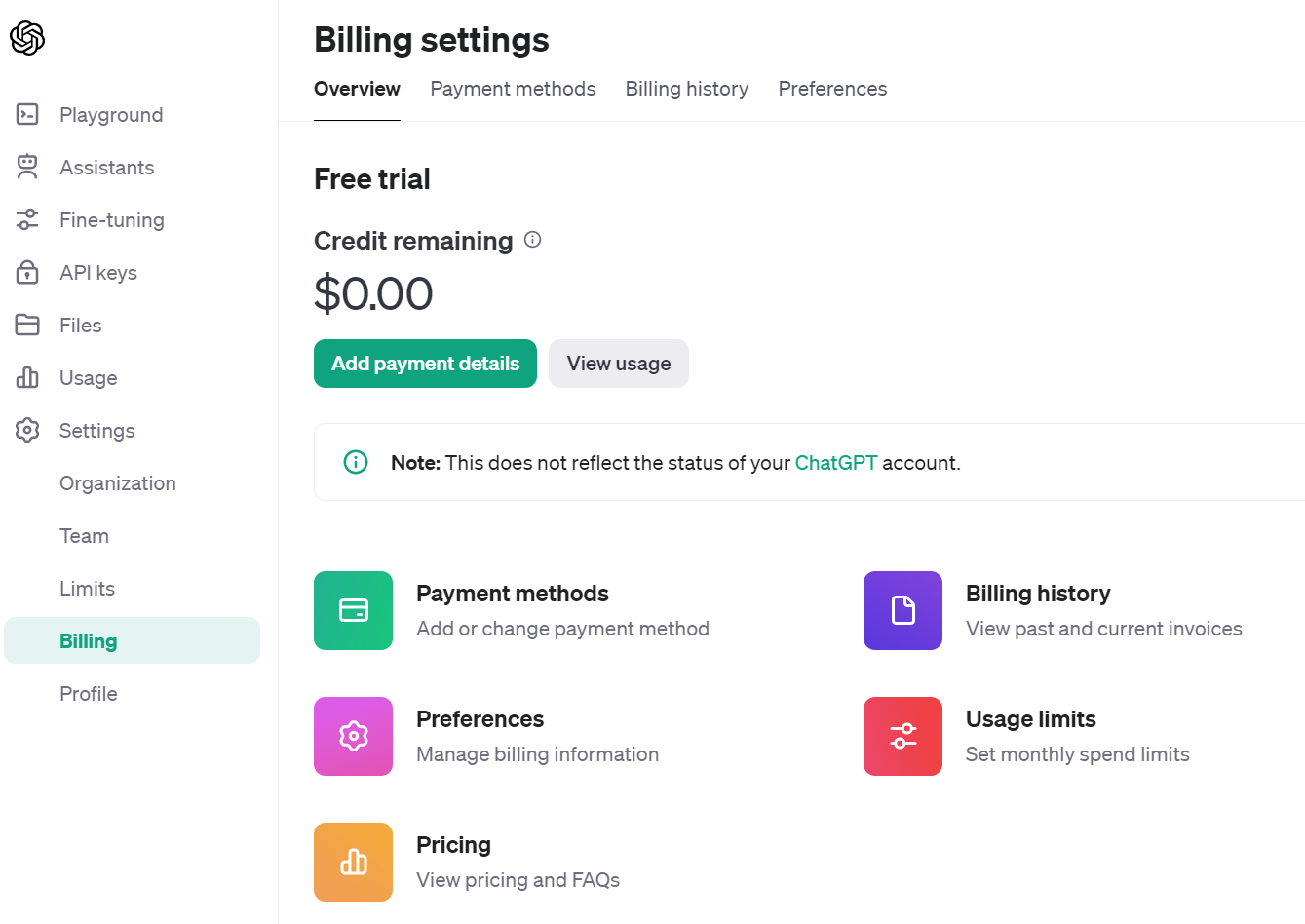
また、Usage limits画面から利用できる金額の上限を設定できるため、使用金額を調整できます。
「Hard limit」は上限金額、「Soft limit」は通知メールが届く金額を設定できるため、使いすぎを防止できるでしょう。
ChatGPTでファインチューニングする際の注意点
ChatGPTのファインチューニングは便利な面がある一方、使用時には以下3つの事項に注意す必要があります。
それぞれの注意点を押さえていきましょう。
ChatGPTでファインチューニングする際の注意点1:大量のクオリティが高い学習データ量が必要
ファインチューニングを利用して、ChatGPTの学習モデルに追加学習させるためには、クオリティが高い大量の学習データが必要です。
適切なデータ量や質が伴っていない場合、希望していた品質のモデルにならない可能性があります。
時間がかかるかもしれませんが、ファインチューニングする場合は質が高い大量のデータを集めましょう。
ChatGPTでファインチューニングする際の注意点2:コストがかかる
ファインチューニングを利用してChatGPTモデルを学習させるには、料金が発生します。
ChatGPT無料版(GPT-3.5)であれば、学習は0.008$(1000トークン当たり)、テキスト入力は0.030$、テキスト出力は0.060$の料金が必要です。
学習データ量が多くなければ精度の高いファインチューニングはできないものの、多いと料金が高額になってしまいます。
そのため、使う上限金額を決めたうえで、ファインチューニングを使用しましょう。
ChatGPTでファインチューニングする際の注意点3:メンテナンスやアップデートの必要がある
ファインチューニングして学習したモデルでも、学習内容を定期的に更新しなければ、回答出力の内容の質が低下するリスクがあるため、メンテナンスやアップデートが必要です。
メンテナンスやアップデートのためには時間と手間がかかることを踏まえて、ファインチューニングを利用しましょう。
ChatGPT研修「BotCamp」の特徴

わたしたちが提供する「BotCamp」は、ChatGPT研修の使い方を初心者から学べる研修です。
・日々登場する新しいAIツールやGPTsに、インプットが追いつかない
・AIツールの選択肢が多すぎて、自分にとって最適なツールを見つけられない
・生成系AIが仕事にどう役立つのか、あまりイメージできない
・すでに業務にAIを取り入れているが、使い方が適切なのかわからない
・時間をかけて学習しても、投資対効果がよいのか分からない
・プロンプトエンジニアリングって難しそう。とっつきづらく感じている
このようなお悩みをお持ちの方におすすめです。
BotCampの特徴1:プロンプトを難しく考えずシンプルに捉える
生成AIからのアウトプットの質を高めるコツは、指示文を「端的に・具体的に」書くことです。
だらだらと長く書く必要はありません。プログラミングやシステムエンジニアリングのように、用語めいた難しい言葉を使う必要も一切ありません。
「プロンプトエンジニアリング」と聞くとやや学術的で高度な技術的理解が必要な印象を受けるかもしれませんが、Prompt Simpleという考え方で、誰でも最小限の労力で最大限AIパワーを活用する方法をお伝えします。
BotCampの特徴2:便利なGPTsを厳選して紹介
GPT storeにて日々増え続ける膨大なGPTsのうち、業務改革のインパクトが大きく重要なGPTsを厳選して紹介します。
業務の種類ごとに、どのGPTを使うべきか自分で考え判断できる応用力を身につけることができます。
BotCampの特徴3:Advanced Data Analysis(旧Code Interpreter)で「一億総データサイエンティスト」に
CSV、PDFなどのデータをアップロードした上で、ChatGPT上でPythonのコードを生成・実行できる機能「Advanced Data Analysis」を活用し、高度な専門性がなくても誰もがデータサイエンティストのようなモデル作成、データの予測ができるようになります。
BotCamp開催概要
| 開催日程 | 研修内容ページを確認 |
| 研修時間 | 9:00~17:00もしくは10:00-18:00 |
| 開催形式 | 対面のみ(オンライン参加不可) |
| 会場 | 水道橋開催の場合 コンフォート水道橋 東京都千代田区神田三崎町2-7-10 帝都三崎町ビル 2階,5階 https://www.relo-kaigi.jp/comfort-suidoubashi/access/ 神田開催の場合 BIRTH KANDA 東京都千代田区神田錦町1-17-1 神田髙木ビル7F https://birth-village.com/ |
| 備考 | ・ChatGPT(GPT-4)が入ったWindowsPCをお持ちください ・推奨のOSはWindowsです。Macでの受講はご遠慮ください。 ・セキュリティ上ChatGPTが使えないPCでの受講はご遠慮ください。 |